 记录精彩人生
记录精彩人生 事务
- 事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成
- 逻辑单位:事务是一个整体,不能分割
- 操作序列:多个DML操作
- 事务有四个特性
- 原子性:事务是最小单位不可分割
- 一致性:事务执行前后的数据总状态是一致的
- 隔离性:事务之间的操作应该是透明的,并发互不影响
- 持久性:对数据的修改只要commit 之后,就是存储到磁盘上的
-
使用事务
- 开启事务:使用
begin;命令或者start transaction命令显式开启事务, - 关闭事务:在执行
commit;命令或者roolback;命令后事务关闭。如果是界面客户端比如navicat开启,当窗口关闭事务也会关闭
- 开启事务:使用
原子性保证
-
原子性的保证是通过undo_log来实现的。
-
insert undo log
-
insert操作产生的undo_log,在事务提交之后就删除
-
结构说明

-
Next Record Offset:两个字节,记录后继Undo Record的位置 -
Type And Flags:对应的日志类型。TRX_UNDO_INSERT_REC表示insert操作的undo日志类型。 -
Undo Number:是Undo的一个递增编号。 -
Table ID:用来表示是哪张表的修改。 -
Key Fields:记录Record完整的主键信息,回滚的时候可以通过这个信息在索引中定位到对应的Record。长度不定,因为对应表的主键可能由多个Field组成
Field- Length表示主键列占用的存储空间,比如int类型占用4个字节。
Field-Content表示主键列的值。
-
Prev Record Offset:两个字节,记录其前序Undo Record的位置。
-
-
数据库中每条记录都会有隐藏字段
-
trx_id:插入或更新行的最后一个事务的ID,自动递增(创建版本号),占用6字节
-
roll_pointer:回滚指针(删除版本号)指向 undo log 记录,占用7字节
-
row_id:行标识,占用6个字节

-
-
当我们向这个表中插入一条记录的时候
-
它会向聚簇索引中插入记录,同时向二级索引中也需要插入记录(假如存在二级索引)。
-
同时,向Undo_Log中插入一条
TRX_UNDO_INSERT_REC类型的UNDO_LOG, -
同时插入的这条记录的roll_poriter指针指向这个UNDO_LOG

-
-
-
Update undo log
-
delete和update操作产生的 undo log
-
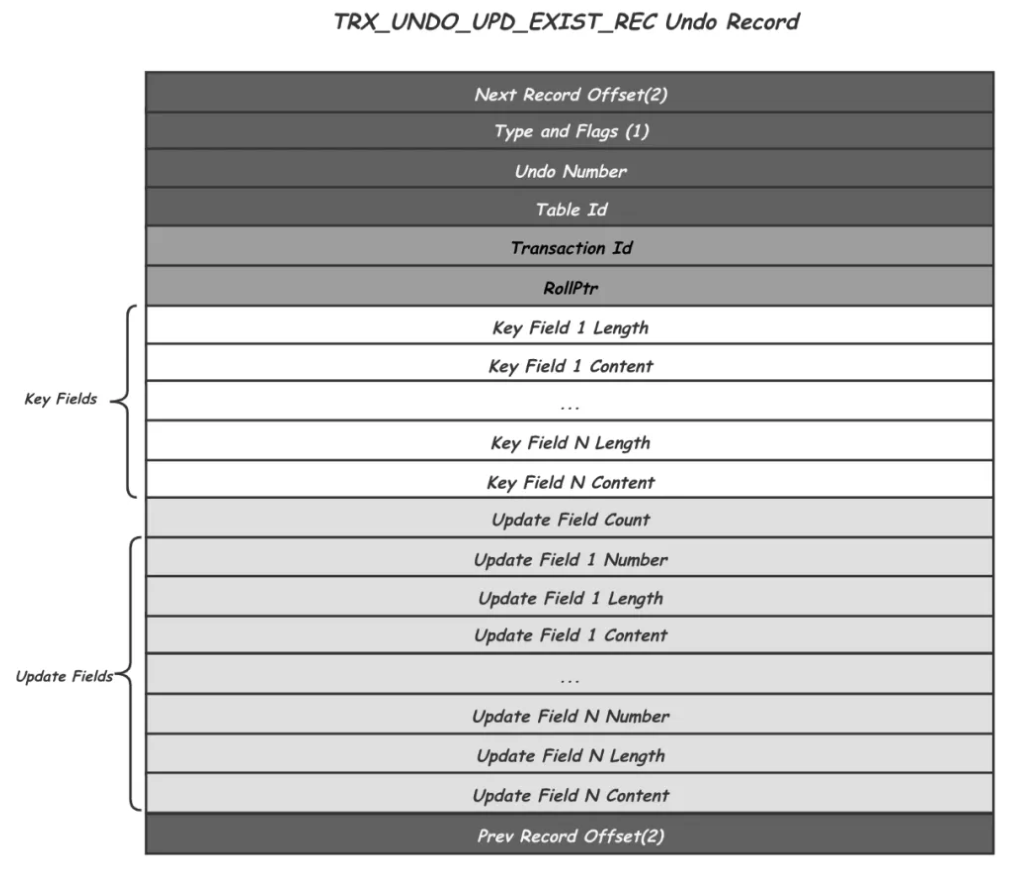
存储结构
-
Next Record Offset:两个字节,记录后继Undo Record的位置 -
Type And Flags:对应的日志类型 -
Undo Number:是Undo的一个递增编号。 -
Table ID:用来表示是哪张表的修改。 -
Transaction Id,记录了产生这个历史版本事务Id,用作后续MVCC中的版本可见性判断 -
Rollptr,指向的是该记录的上一个版本的位置,沿着Rollptr可以找到一个Record的所有历史版本。 -
Key Fields:记录Record完整的主键信息,回滚的时候可以通过这个信息在索引中定位到对应的Record。长度不定,因为对应表的主键可能由多个Field组成
Field- Length表示主键列占用的存储空间,比如int类型占用4个字节。
Field-Content表示主键列的值。
-
Update Fields中记录的就是当前这个Record版本相对于其之后的一次修改的Delta信息,包括所有被修改的Field的编号,长度和历史值。
-
Prev Record Offset:两个字节,记录其前序Undo Record的位置。
-
- 当一个事务要更新一行记录时,会把当前记录当做历史快照保存下来,多个历史快照会用两个隐藏字段trx_id和roll_pointer串起来,形成一个历史版本
链,当需要事务回滚时,可以依赖这个历史版本链将记录回滚到事务开始之前的状态,从而保证了事务的原子性(一个事务对数据库的所有操作,要么
全部成功,要么全部失败)
- 数据库中的每行数据除了隐藏字段
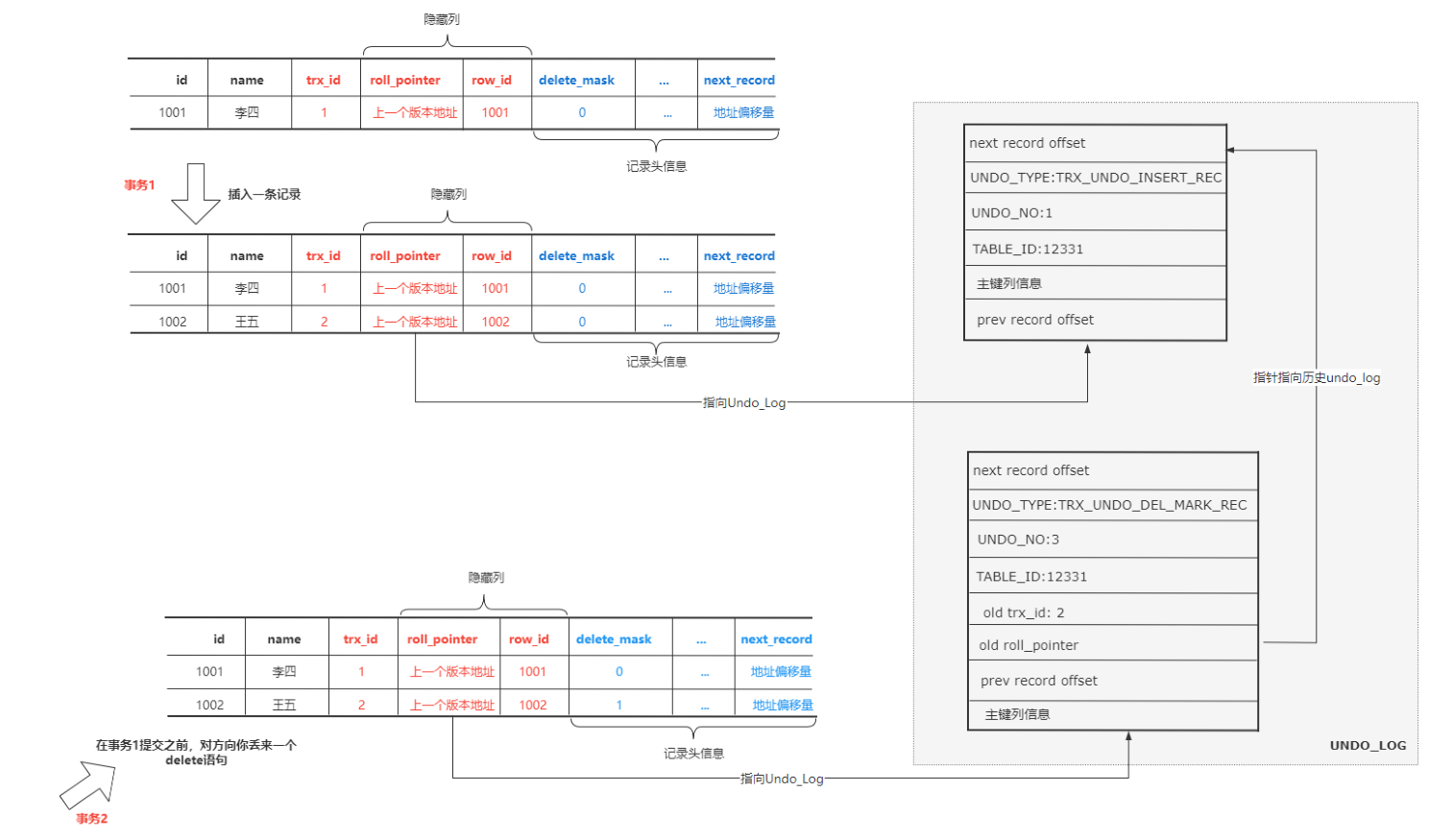
trx_id、row_id、roll_pointer之外还有记录头信息 - 当我们插入一条记录后,又删除了这条数据
- 当我们插入一条记录后,该记录的 roll_pointer 指向
TRX_UNDO_INSERT_REC类型的 undo log(insert undo log) - 这时我们用 delete 删除该记录(事务未提交,执行阶段一),生成一条
TRX_UNDO_DEL_MARK_REC类型的 undo log( delete undo log)。 - 这条记录的记录头信息中的Delete Mark标记为
1 - 此时该记录仍存在,且 roll_pointer 指向 delete undo log,delete undo log 的 old roll_pointer 指向 insert undo log
- 当更新一条数据的主键时,会生成两条undo log
- 对目标记录进行delete_mask标记之前,会记录一条类型为
TRX_UNDO_DEL_MARK_REC的undo log - 之后再插入新的记录时,会记录一条类型为
TRX_UNDO_INSERT_REC的undo log
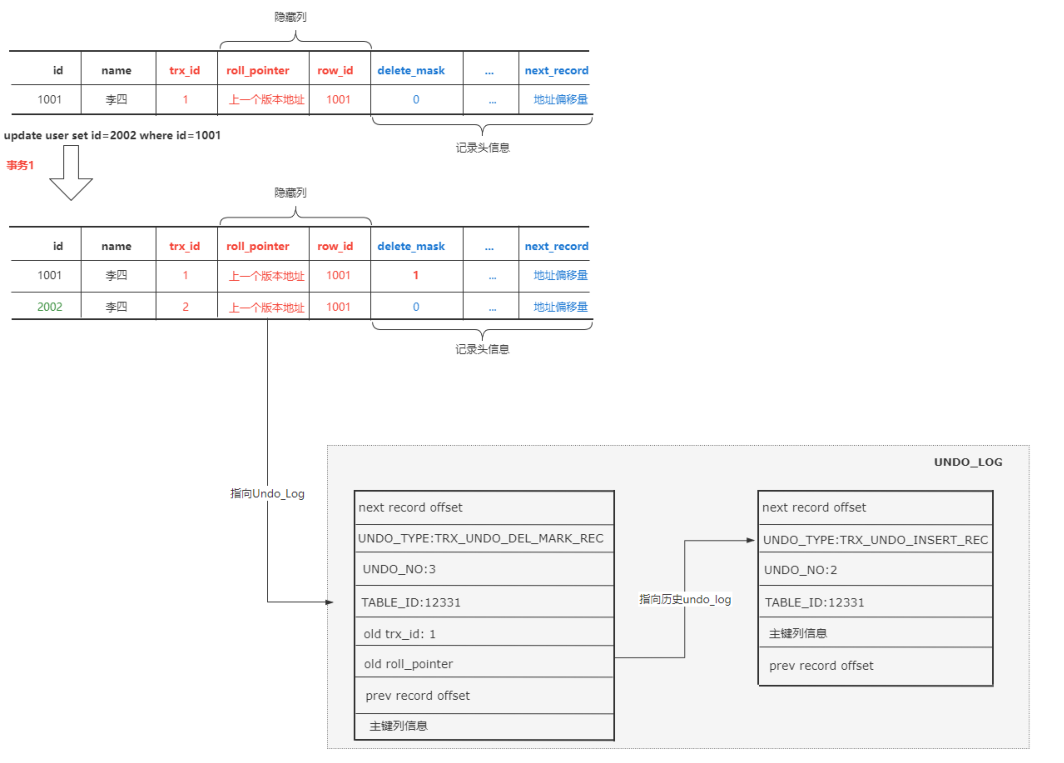
- 对目标记录进行delete_mask标记之前,会记录一条类型为
-
当更新一条数据时,不更新主键
-
如果 更新的列占用的存储空间 不发生变化,直接可以在原来的记录上修改。
-
如果 更新的列占用的存储空间 发生变化,会先在聚集索引中删除这条记录,然后再根据更新后的值创建一条新记录。
这里的删除,就不是像前面那样直接修改delete_mask,而是由用户线程同步执行真正的删除
因为这里有锁的保护,并不存在并发问题因为这里有锁的保护,并不存在并发问题
-
-
-
实例:
-
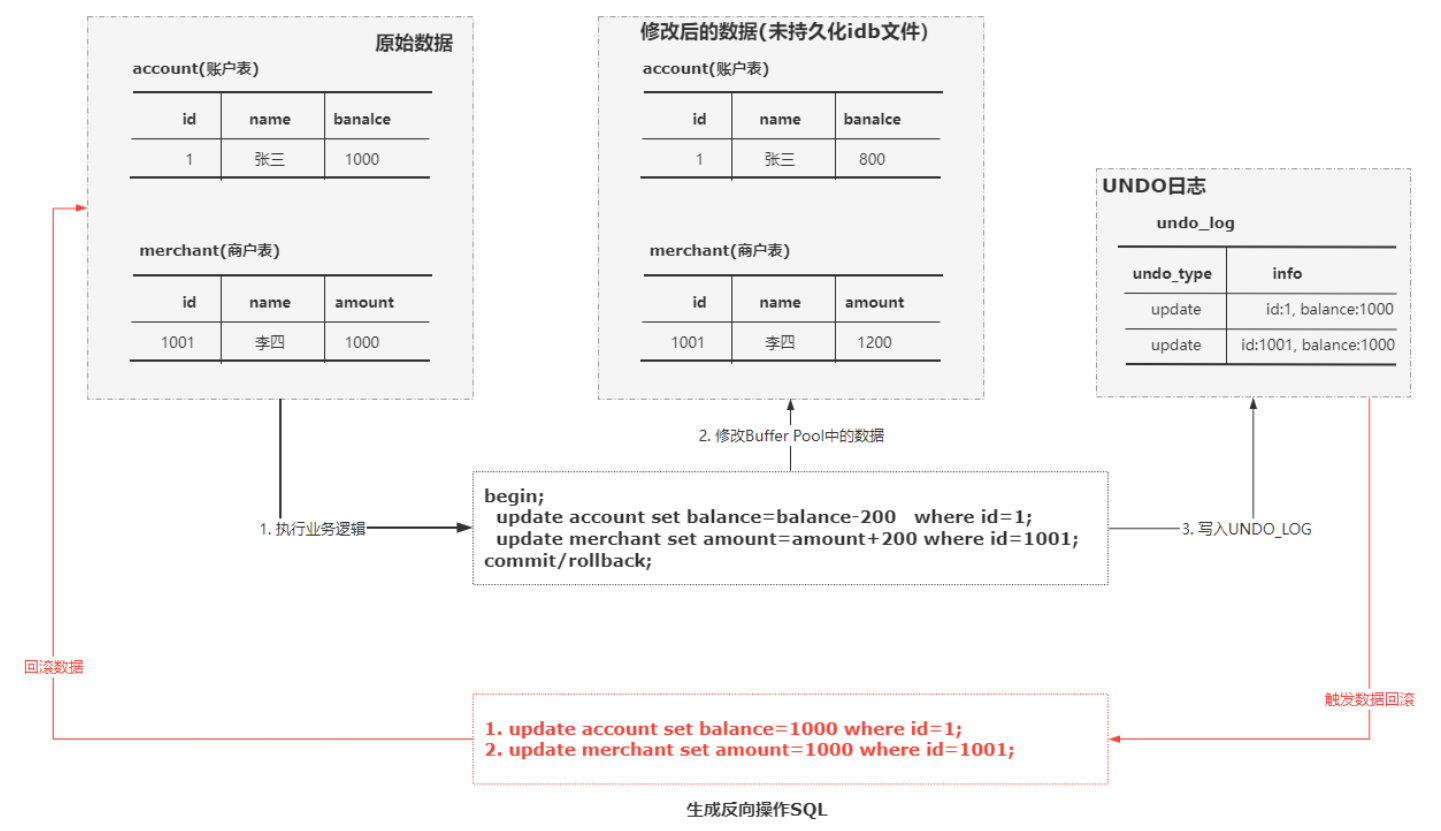
需要对商户库存和账户进行操作
begin; update account set balance=balance-100 where userid=1; update merchant set amount=amount+100 where mid=10001; commit; -
此时会修改Buffer Pool中的数据,同时会将原始数据记录到undo_log中,如果发生回滚则通过undo_log实现
-
读一致性问题
- 事务并发会带来读一致性问题
- 脏读:事务A读取到了事务B未提交的数据,导致事务A两次执行查询获取的结果不一致

- 不可重复读:事务A读取到了事务B提交的数据,导致事务A两次执行查询获取的结果不一致,数据总量不变
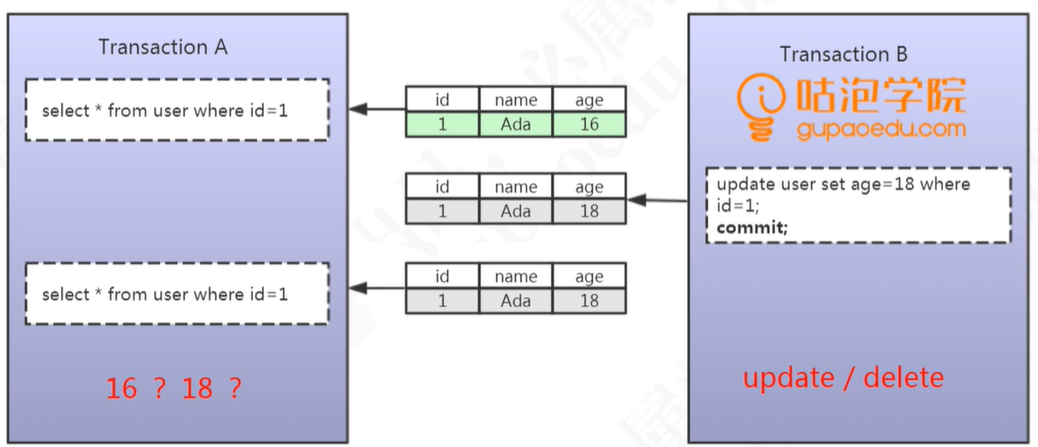
- 幻读:事务A读取到了事务B提交的数据,导致事务A两次执行查询获取的结果不一致,数据变多

- 脏读:事务A读取到了事务B未提交的数据,导致事务A两次执行查询获取的结果不一致
事务隔离
- 数据库的读一致性问题,需要通过数据库来提供事务隔离机制进行解决。专家于1992年制定了一系列事务隔离机制的标准
- Read Uncommitted(未提交读)——并未解决任何并发问题
- 事务未提交的数据对其他事务时可见的,会出现脏读
- Read Committed(已提交读)——只解决了脏读问题
- 一个事务开始后,只能看到已提交的事务所作的修改,会出现不可重复读以及幻读
- Repeatable Read(可重复读)——解决了不可重复读问题
- 在同一事务中多次读取同样的数据结果是一样的,会出现幻读
- Serializable(串行化)——解决所有问题
- 最高隔离级别,强制串行执行
- Read Uncommitted(未提交读)——并未解决任何并发问题
-
要解决读一致性问题,事务隔离机制的具体实现有两种解决方案:
-
LBCC(Lock Based Concurrency Control):在读取数据前,对其加锁,阻止其他事务对数据进行修改
-
MVCC(Multi Version Concurrency Control):读取数据的时候生成一个数据请求时间点的一致性快照,后续操作都读取快照数据
InnoDB提供了两种事务隔离级别的解决方案实现,两种方案是协同使用的
-
-
InnoDB 的MVCC方案实现:
-
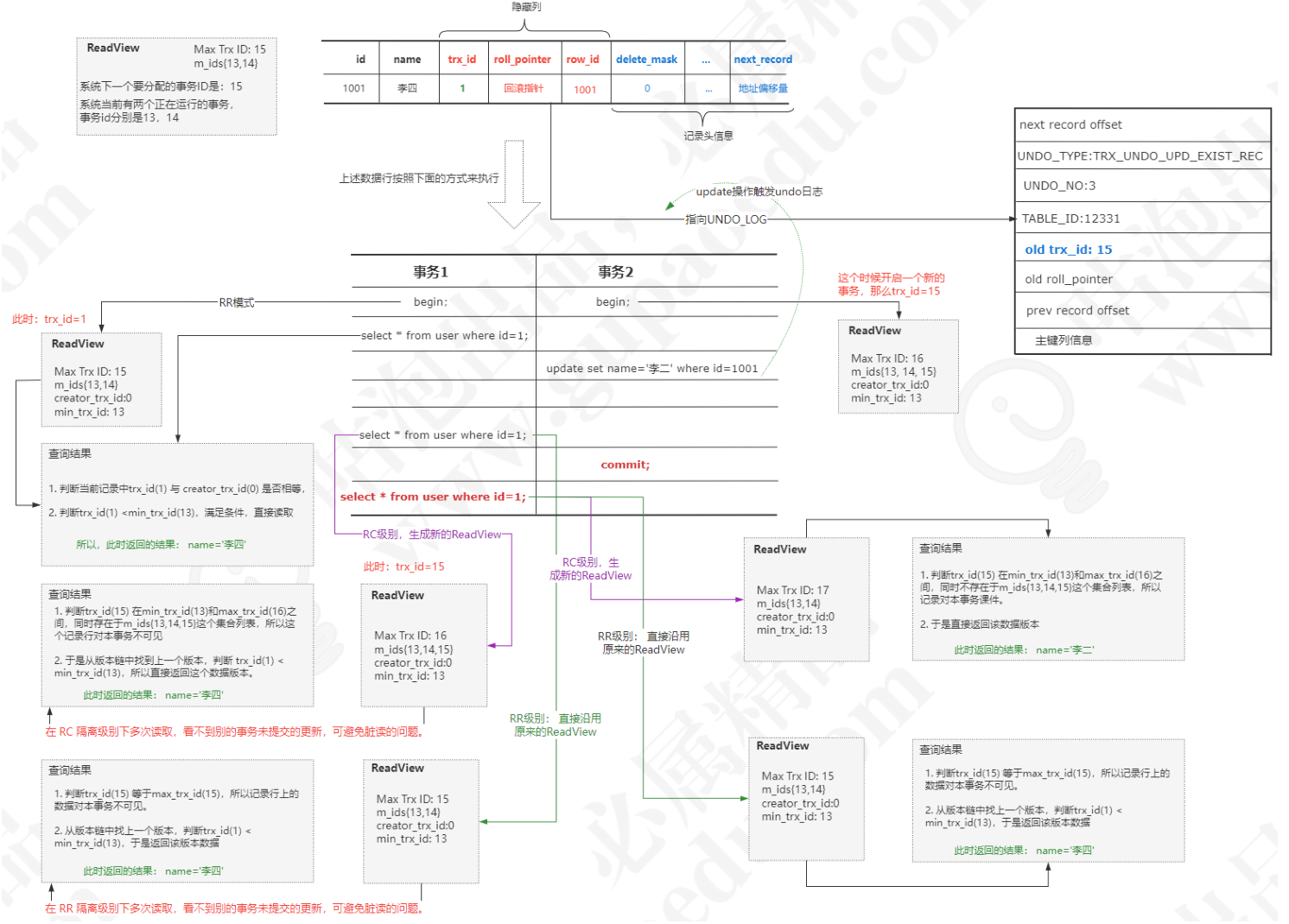
每次开启一个事务的时候,都会创建一个Read View对象,以此来实现一个事务对另外一个事务的可见性。每个Read View对象有以下属性

-
数据库中每条记录都会有隐藏字段
-
trx_id:插入或更新行的最后一个事务的ID,自动递增(创建版本号),占用6字节
-
roll_pointer:回滚指针(删除版本号)指向 undo log 记录,占用7字节
-
row_id:行标识,占用6个字节

-
-
判断逻辑
-
如果 trx_id 等于 creator_trx_id,说明当前事务在访问它自己修改过的记录(本事务修改),所以这个版本可以被当前事务访问。
-
如果 trx_id 小于 min_trx_id,说明在Undo版本链中的这个事务在当前事务生成 Read View 前已经提交,所以这个版本可以被当前事务访问。
当前事务在执行的时候, 这个快照已经生成了
-
如果 trx_id 大于或等于max_trx_id,说明在Undo版本链中的这个事务在当前事务生成 Read View后才开启,所以这个版本不可以被当前事务访问。
-
如果 trx_id 在 min_trx_id 和 max_trx_id 之间,此时再判断一下 trx_id是不是在 m_ids 列表中。
-
如果在,说明创建Read View时生成该版本的事务还是活跃的,该版本不可以被访问;
-
如果不在,说明创建Read View时生成该版本的事务已经被提交,该版本可以被访问。
-
-
RC ,每次查询前都会生成一个独立的Read View。RR,只是在第一次查询前生成一个Read View,之后的查询都重复使用这个Read View
-
-
InnoDB 的锁实现方案
-
锁是用来解决资源竞争问题的,即事务对于数据的并发访问问题。数据库的资源无非是数据表和数据行,锁分类为行锁和表锁
-
行锁--共享锁(Shared Locks):共享锁又称为读锁,多个事务对于同一个数据可以共享一把锁,都能进行数据访问。只能读不能修改;
- 使用
select * from user where id = 1 lock in share mode加读锁 - 使用
commit或者roolback释放锁
- 使用
-
行锁--排他锁(Exclusive Locks):排他锁又称为写锁,如果一个事务获取了一个数据的写锁,那么其他事务就不能获取该数据的锁(包含共享锁和排他锁)。只有获取了排他锁的事务可以对数据进行修改和读取
delete \ update \ insert语句会自动加入写锁- 使用
select * from user where id = 1 for update加写锁 - 使用
commit或者roolback释放锁 - 通过
show variables like '%timeout%'查看获取不到锁的等待时间,超过该时间会放弃等待获取锁
- 表锁属于意向锁,意向锁是通过存储引擎自己维护的,用户无法手动操作。
- 加表锁的前提:表中的任一行数据都没有被任意事务锁定。
- 要确定这个前提,就需要针对表数据全表扫描,比较耗时。
- 为了节约时间,在每个表上有个意向锁的标志位,要加锁的时候只要查看该标志位即可
- 表锁理解为标志位即可
- 表锁类型:意向共享锁(Intention Shared Locks)、意向排他锁(Intention Exclusive Locks)
- 加表锁的前提:表中的任一行数据都没有被任意事务锁定。
-
- 锁的原理:行锁是通过锁住聚集索引来实现的,因此会有以下情况发生
- 如果存在主键,那么对主键加锁
- 如果不存在主键,存在唯一索引,那么会针对唯一索引加锁
- 如果既不存在主键也不存在唯一索引,那么会通过ROWID进行锁定,表现为锁表
-
行锁实现算法
-
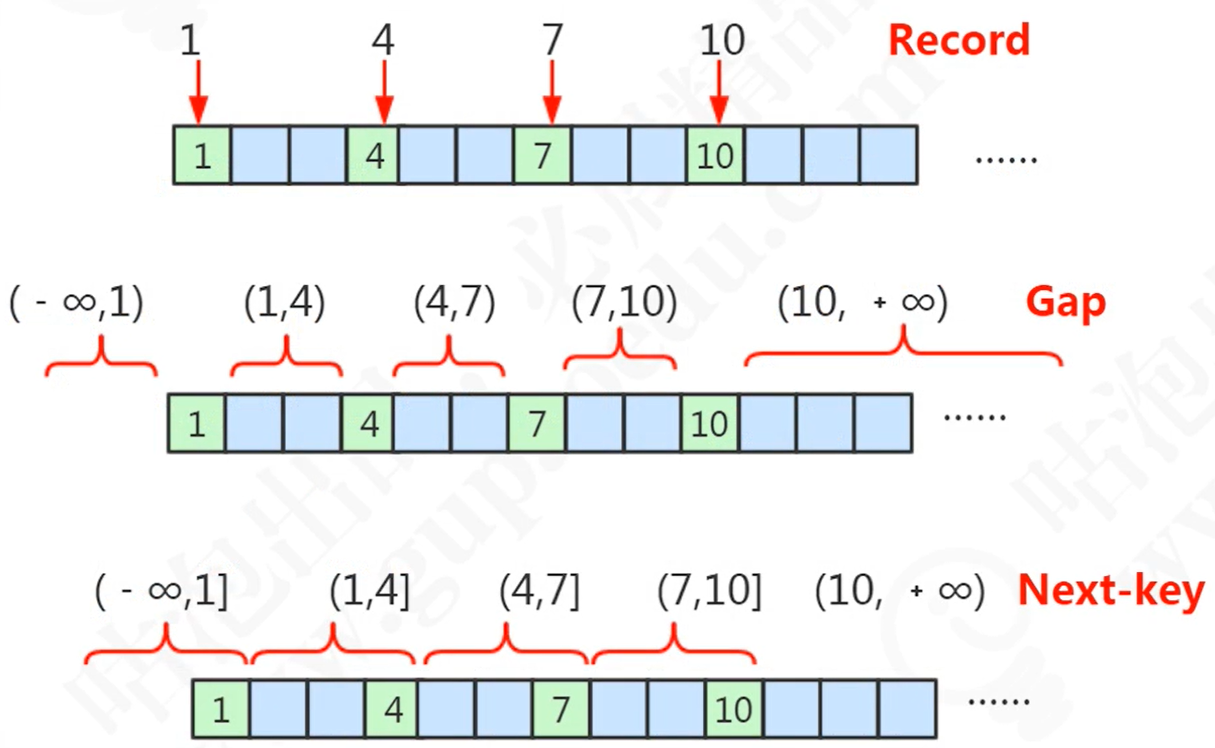
实现算法有Record(记录锁)、Gap(间隙锁)、Next-key(临键锁)。(非数字也会根据ASCII码进行排序)
-
举个例子
-
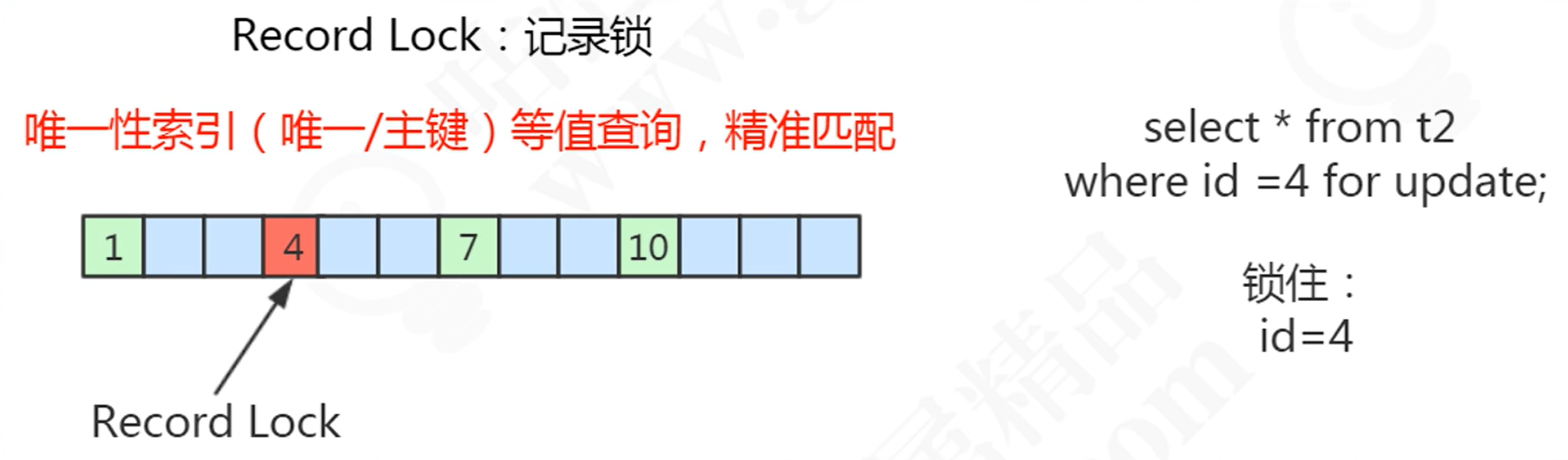
假如有一张表,表结构与数据如下:
create table tt( id int(11) not null, name varchar(255) default null, primary key(id) ) Engine = innodb default charset=utf8; insert into tt (id,name)values(1,'1'); insert into tt (id,name)values(4,'4'); insert into tt (id,name)values(7,'7'); insert into tt (id,name)values(10,'10'); -
记录锁(Record Locks):锁定记录
-
间隙锁(Gap Locks):锁定范围
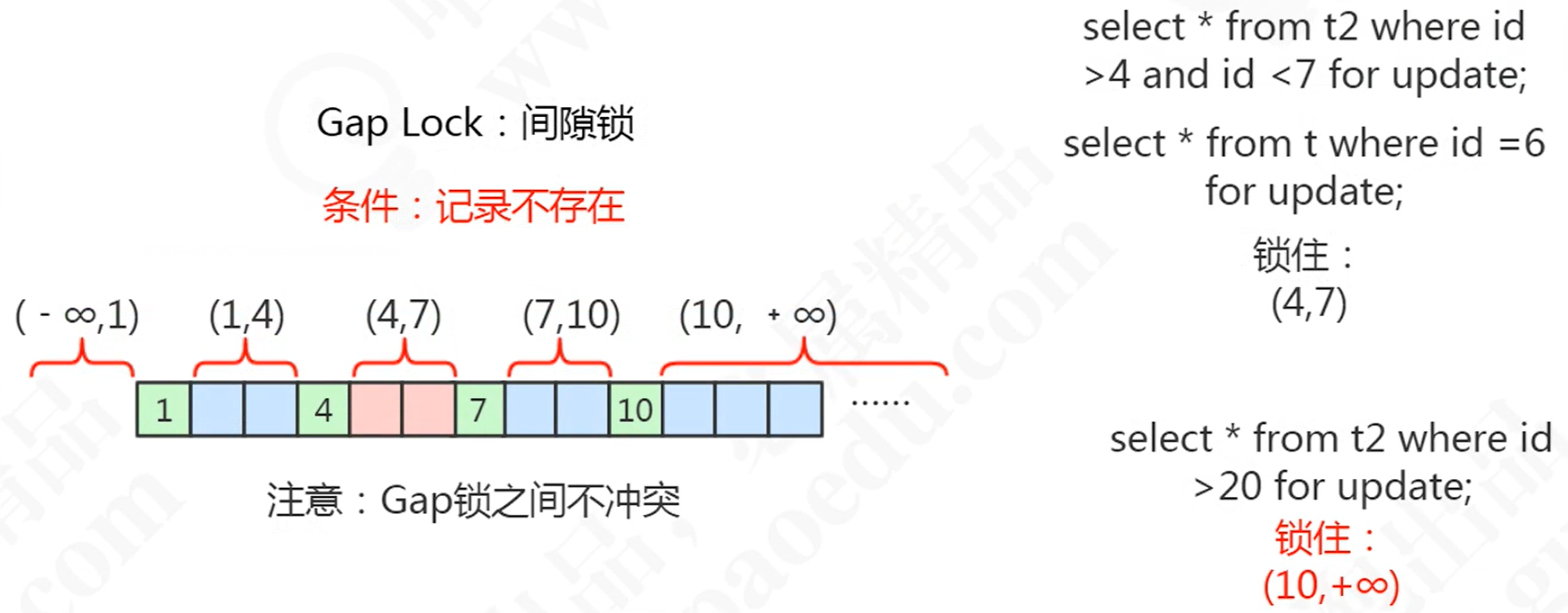
-
临键锁(Next-key Locks):锁定范围+记录
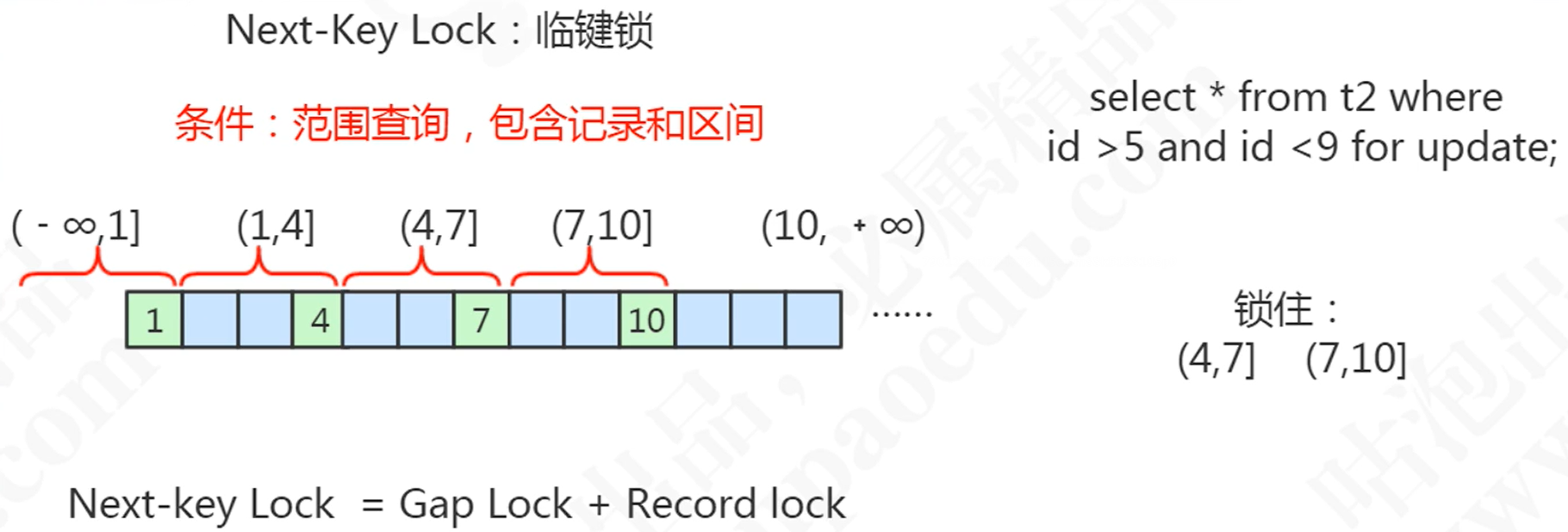
-
-
间隙锁(Gap Lock) 会导致锁定范围扩大,临建锁(Next-key Lock) 会导致锁定范围扩大,因此使用时尽量更改语句,让其使用记录锁
-
- 不同数据库提供的事务隔离的实现是不同的比如Oracle就只有RC和S两种,MySQL InnoDB提供了以下的隔离级别
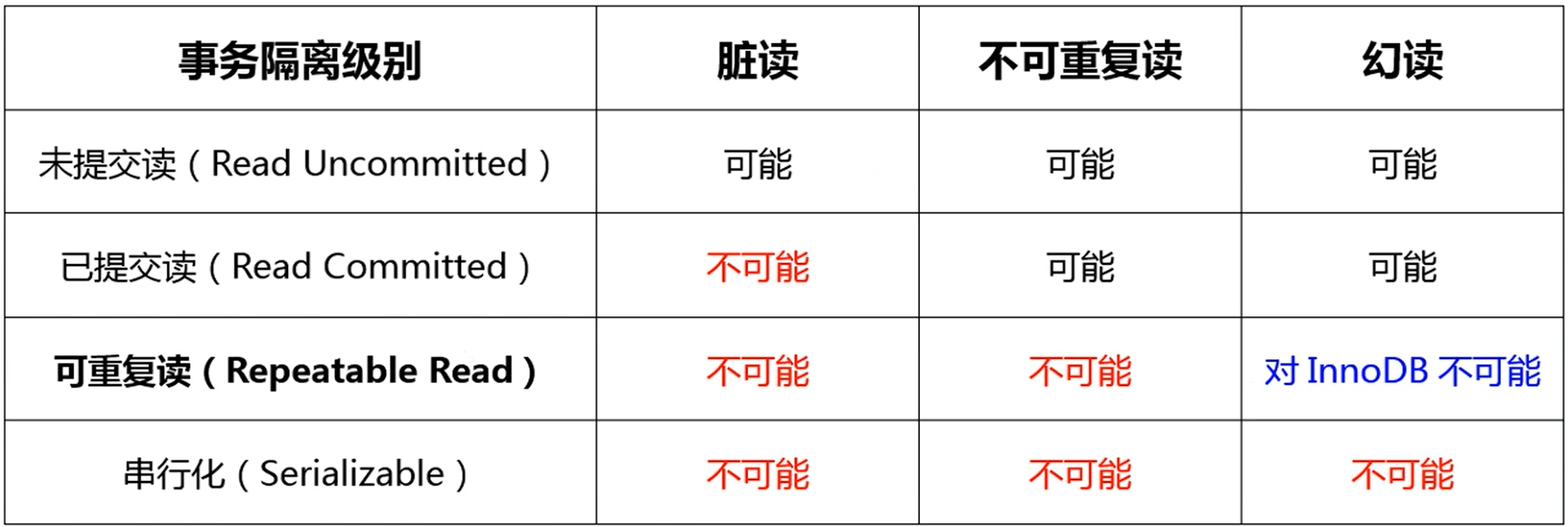
-
InnoDB的隔离级别说明
-
RU(Read Uncommitted) :不加锁
-
RC(Read Committed ):
- 普通 select :使用MVCC机制
- 加锁的 select 和 更新:使用记录锁
-
RR(Repeatable Read):默认的隔离级别
- 普通 select :使用MVCC
- 加锁的select 和更新,底层使用记录锁、或者间隙锁、临键锁。
-
Serializable
- 所有的
select语句会被隐式转化为select …… in share mode,会和update、delete互斥
- 所有的
-
Read Committed 和 Repeatable Read 对比
- RR的间隙锁会导致锁定范围扩大,当使用的查询没有查询到数据会锁表,RC不会锁表
- 带锁的select 条件列未使用到索引的数据,RR会锁表,RC 会锁行
- RC 的半一致性读可以增加update操作的并发性
-
使用数据库的默认隔离级别RR即可
-
优化
-
配置优化
-
数据库最大连接数优化
查看最大连接数命令
show variables like 'max_connections';查看已经连接到数据库的最大连接数
show variables like 'max_used_connections';比较理想的设置是:
max_used_connections / max_connections * 100% ≈ 85% -
减少连接释放等待时长
查看释放等待时长:
show global varivables like 'wait_timeout'; -
架构优化
使用数据库集群增加服务器承受压力
-
-
客户端:
-
使用连接池,实现连接的复用,减少客户端的连接
- 连接池的大小可以使用以下公式操作: 数据库服务器CPU核心数 * 2 +1
-
架构方面优化
- 使用缓存减少连接
- 使用基于主从复制的读写分离
-
-
参数优化参考官网MySQL :: MySQL 8.0 Reference Manual :: 5.1.8 Server System Variables
-
架构层次优化
- 增加缓存服务,提高运行速率,减少数据库压力
- 单台服务器进行垂直分库,以业务角度进行区分,减少数据库并发访问压力
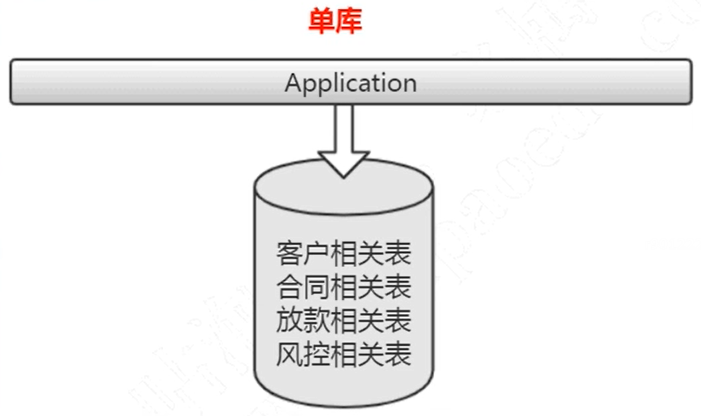
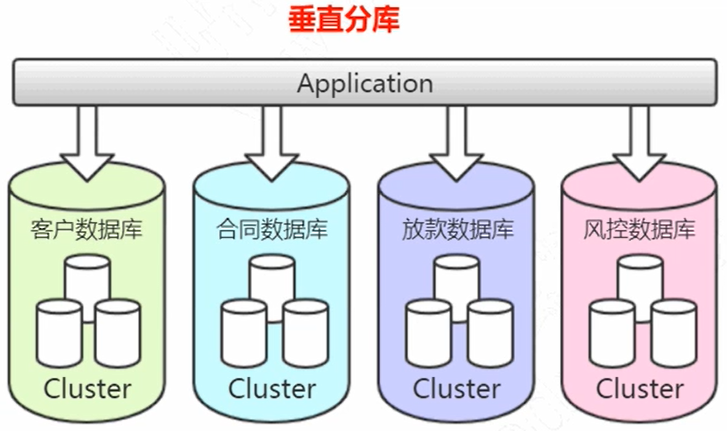
- 使用水平分库分表,以一定的规则进行划分,解决存储瓶颈
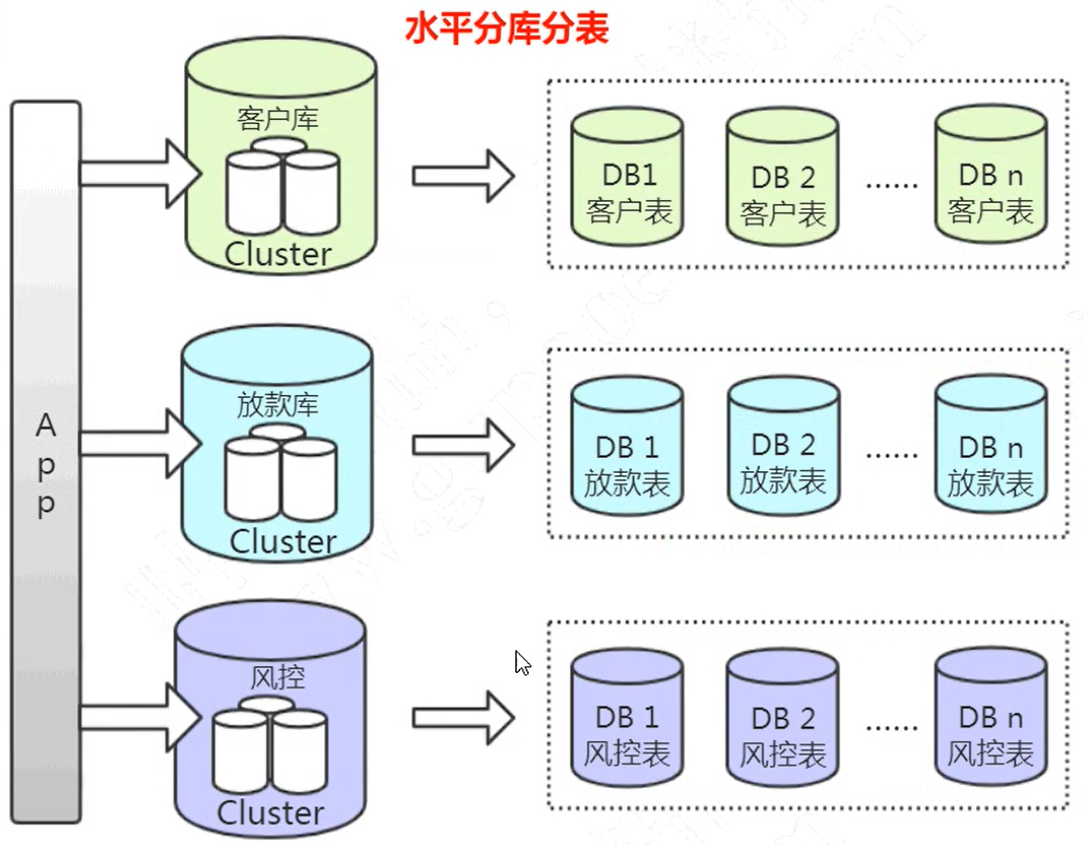
- 采用数据库集群,减少单台数据库压力
- 使用基于主从复制的读写分离,将读请求和写请求路由到不同的数据库
-
存储引擎表结构优化
-
数据一致性要求较高使用InnoDB,查询和插入比较多使用MyISAM,临时数据使用Memory
-
表优化
- 根据时间进行表结构拆分
- 字段定义:使用正确存储结构的最小类型,比如:性别使用tinyint ,固定字符串定长使用char
- 如果字段业务定义不为空,定义为NOT NULL,并提供默认值 ''
- 不使用数据库的视图、触发器、外键等,会降低可读性,会影响性能
- 大文件存储直接放到文件服务器,数据库存储URI即可
-
-
语句优化
-
开启慢查询日志
-
查询是否开启
show variables like 'slow_query%'; -
开启方式:在配置文件中增加慢查询日志相关的配置
show_query_log = on ## 慢查询的超时时间 单位秒 long_query_time = 2 ## 日志文件位置 slow_query_log_file = /var/lib/mysql/localhost-slow.log
-
-
分析慢查询日志
- 使用
mysqldumpslow对日志文件进行分析统计 - 查看系统线程情况:
show processlist; - 查看数据库运行状态:
show global status; - 查看存储引擎运行状态:
show engine innodb status;
- 使用
-
-
执行计划
-
使用Explain命令查看执行计划,官网:MySQL :: MySQL 8.0 Reference Manual :: 8.8.2 EXPLAIN Output Format
-
Explain结果字段说明
- id:查询的序号,决定访问表的顺序,ID不一致时执行顺序先大后小执行,一致时从上往下。数据量会变更顺序
- select_type:查询类型
- SIMPLE:简单查询,不包含子查询
- PRIMARY:包含了子查询语句的主查询
- SUBQUERY:子查询
- DERIVED:衍生查询,代表临时结果的查询
- UNION:关联查询
- UNION RESULT:联合查询的结果
- type:关联类型
- const:使用了主键索引或者唯一索引查询一条数据
- system:const的特例,查询系统表一条数据
- eq_ref:关联查询时用到了主键索引或唯一索引
- ref:用到了普通索引
- range:用到了索引并对索引进行了范围查询
- index:用到了索引的全部数据
- all:全表扫描,没有索引或者没有用到索引
- Null:不需要索引就会直接获取结果 比如:
select 1 from table where 1 = 1
- possible_key:可能用到的索引
- 复合索引可以出现多个
- key:实际用到的索引
- key_len:使用的索引的长度
- rows:预估扫描值,不准确,越小越好
- ref:用到了哪个字段去筛选
- Extra:额外信息
- using where:存储引擎返回的数据不完全符合条件,在服务层还需要过滤
- using index:使用覆盖索引
- using filesort:无法使用索引排序
- using temporary:在得到结果之前用到临时表
-
分析到表的瓶颈,然后针对瓶颈进行针对优化,使用索引提高效率
-
-
业务层优化
- 业务流程:比如双十一将钱充值到余额宝进行交易有奖励,这样交易时使用内部接口效率更高
- 降级措施:比如双十一当天不能查询之前的交易记录,关闭非核心业务保证交易核心业务
- 预售分流:比如双十一之前就打广告说保障价格跟双十一相同,降低高峰
-
跳脱出关系型数据库 使用搜索引擎或大数据方案