 记录精彩人生
记录精彩人生 
MySQL体系结构
-
整体架构图
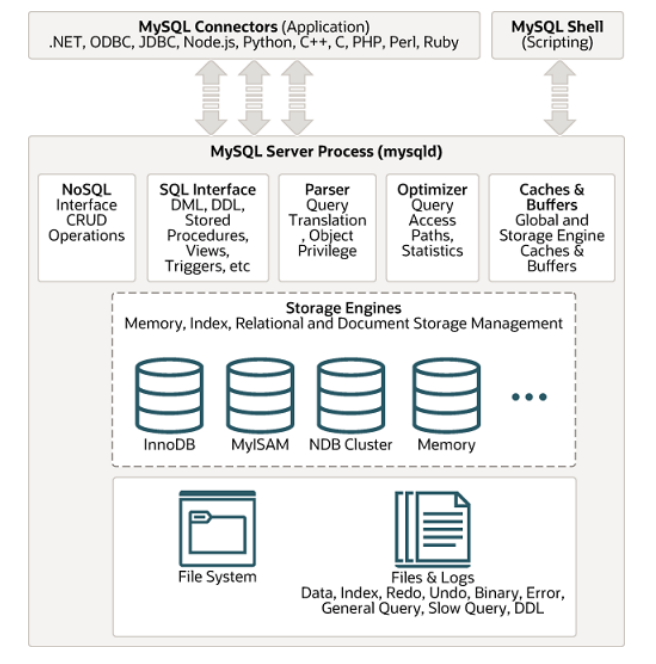
-
由架构图,可以 清晰可见,整体架构分为三层:🏷连接层🏷服务层、🏷存储引擎层,各层级的主要组件以及功能会通过语句查询流程进行体现
-
执行一条查询SQL语句
select name from user_info where id =1 and age>20整体执行流程如下: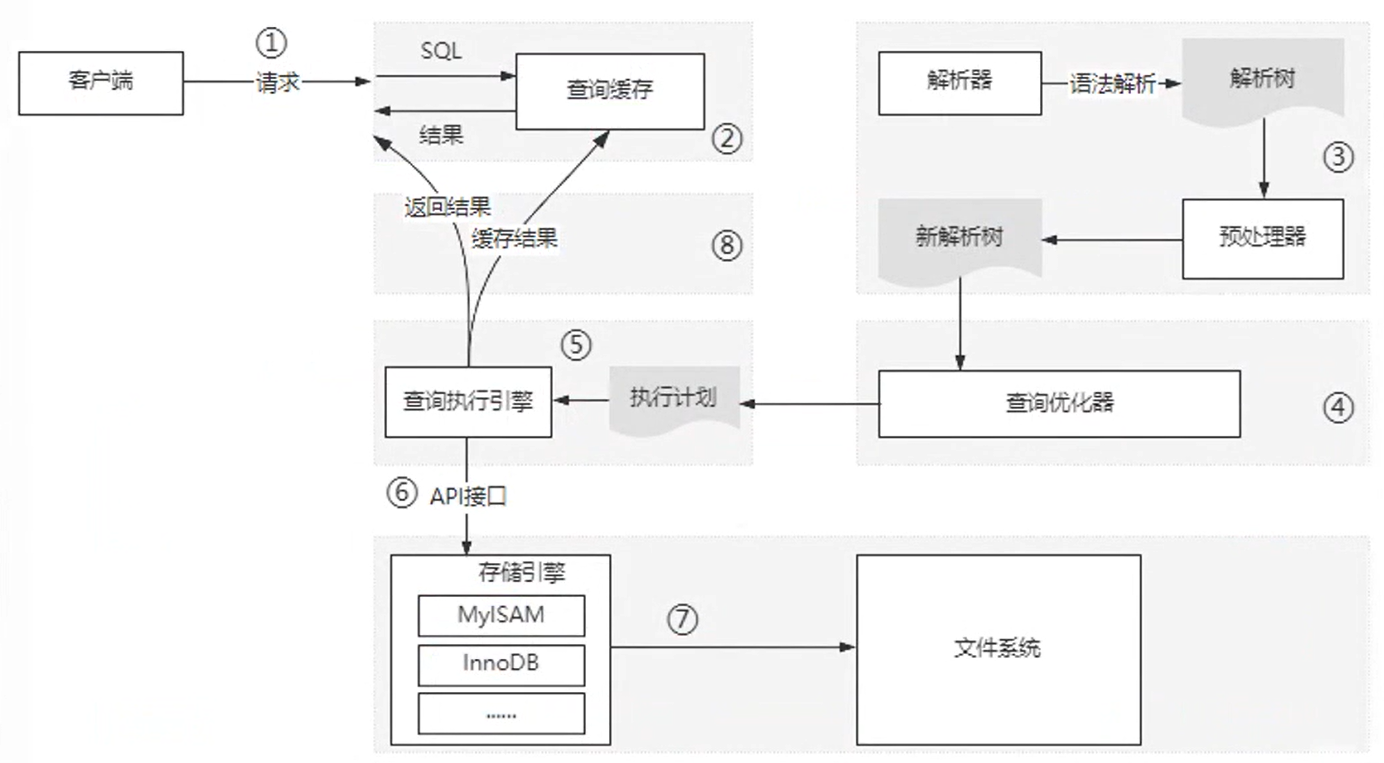
-
建立连接
- 同步通信:客户端发起请求,必须等待服务端返回,期间不能进行其他操作,依赖于服务端性能,只能做到一对一的通信
- 异步:避免客户端的等待,存在并发问题,不建议使用
- 长连接:操作完成之后,其他客户端还可以使用一般使用长连接,放到连接池进行管理
- 短连接:连接操作完成之后马上close
- 使用
show status like 'Thread%';查看连接数 - 通过
show variables like 'max_connections';查看服务端最大连接数 - 动态修改参数
set session/global var_name value,重启后会失效。
-
查询缓存:不推荐使用数据库自带的缓存,使用作用有限,一点变化就导致失效,MySQL版本8已经去除了缓存模块
-
通过解析器和预处理器,对sql语句进行解析
- 解析器通过词法解析、语法解析将语句变为一颗语法树

- 预处理器进行语义解析:查询语句中有不存在的表或字段或者别名不正确,分析用户的权限等
- 解析器通过词法解析、语法解析将语句变为一颗语法树
-
通过优化器进行优化,生成执行计划
- 将语法树变为为查询树,通过查询重写生成执行计划,使用基于成本的优化方案,即 IO次数、CPU计算耗时等,寻找最优的执行计划
- 代价估算公式

-
当一条SQL语句经过Optimizer优化器优化之后,会针对这条SQL产生一个执行计划,从这个执行计划中可以得知Mysql会如何执行这条SQL
- 可以通过
EXPLAIN关键字来查看指定SQL的执行计划 - 可以查看到:表的读取顺序、数据读取操作的操作类型、哪些索引可以使用、哪些索引被实际使用、表之间的引用、每张表有多少行被优化器查
- 可以通过
-
执行器使用API调用存储引擎完成数据查询
-
存储引擎
-
存储引擎是MySQL数据库的一个特色,存储引擎层负责存储与管理数据,不同存储引擎决定了数据存储结构以及数据管理方式。
- 使用
select version();查看数据库版本号,使用show ENGINES;查看支持的存储引擎。 - 存储引擎的使用是以表为单位的,
show VARIABLES like 'datadir';查看表文件存储路径
- 使用
-
不同存储引擎对比

-
MyISAM存储引擎:MySql5.5版本之前默认的存储引擎,支持表级别的锁定,适合只读为主的数据,存储了表的行数,所以使用count 比较快
-
InnoDB存储结构模型
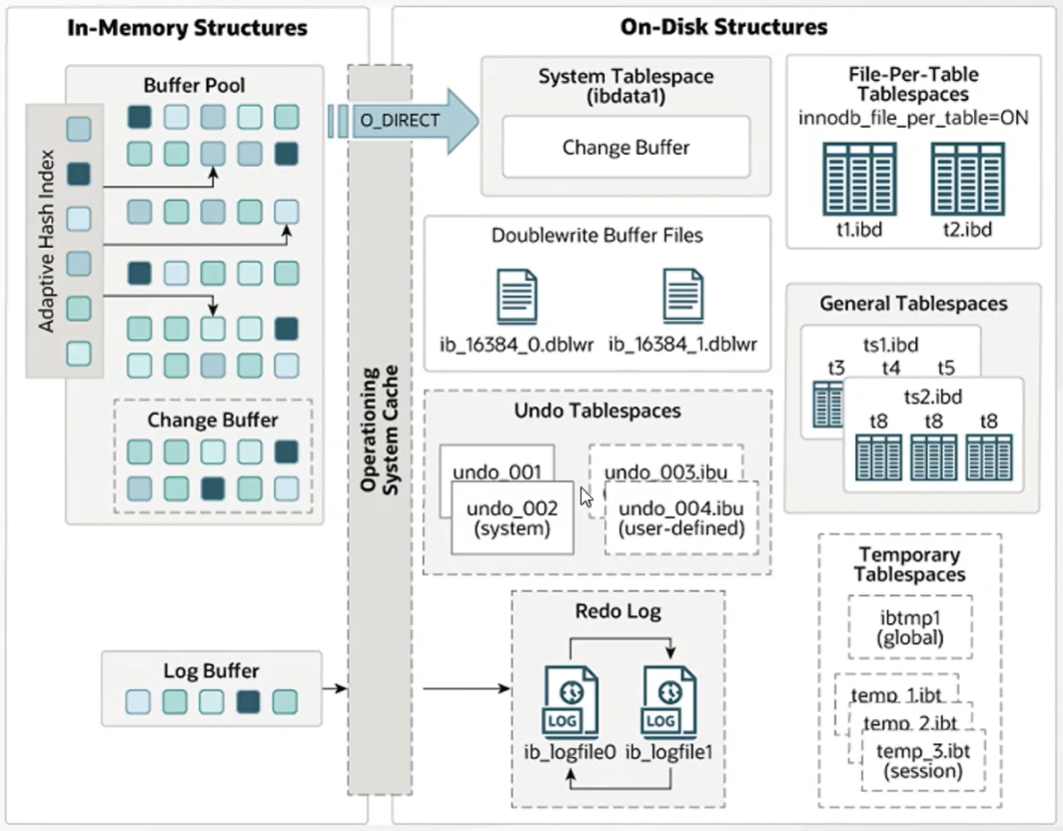
InnerDB内存结构
- Buffer Pool
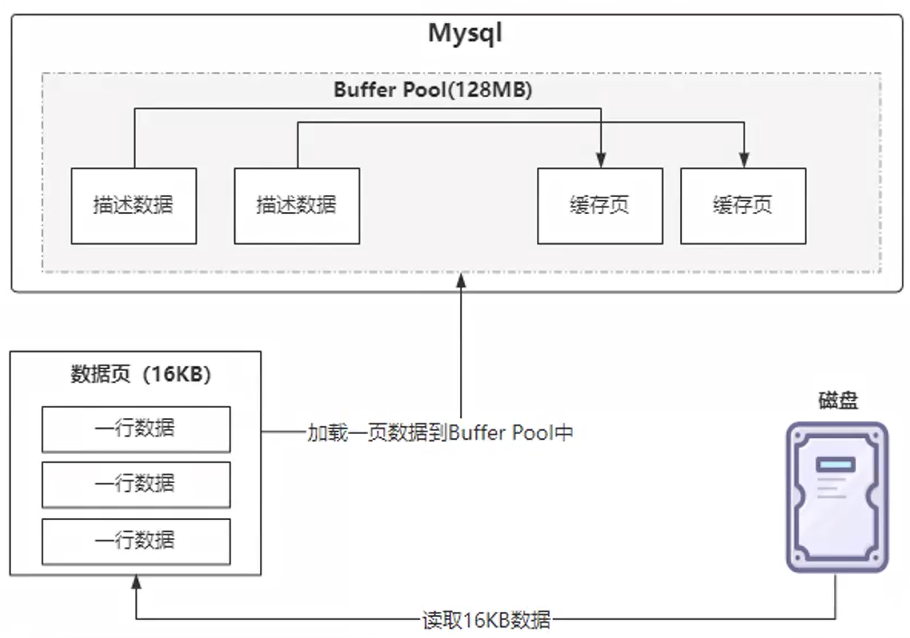
- 存储引擎的数据是存储到磁盘上的DB file 中,如果要修改或查询数据,需要将数据从磁盘加载到内存中。为了性能考虑,读取磁盘的DB file时,会每次读取一个页的大小,放到内存中的专门开辟的名字叫 Buffer Pool的地方。
- 🏷 页:从磁盘加载数据到内存中有一个最小的存储单位:页(page)默认16K(16384 bytes)大小,是个逻辑单位
- 🏷 页的设计包含一个预读思想,提前将部分数据加载至内存中,减少IO次数
- 🏷 Buffer Pool默认大小是128M。
- 用户读取数据时,会先检查该数据在Buffer Pool里面是否存在,如果存在直接读取,否则将磁盘上DB file 中的数据加载到Buffer Pool中进行读取。

- 缓存管理策略
- 所有新的数据页加入到Buffer Pool时,一律先放到冷数据区的head位置,不管是预读数据还是普通的读操作。
- 如果这个数据页在LRU链表中冷数据区存在的时间超过了1秒,就把它移动到热数据区
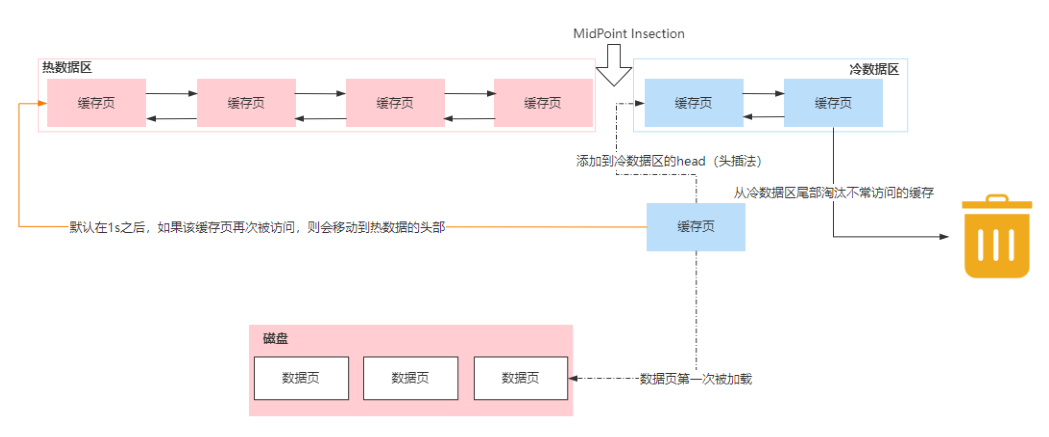
- 存储引擎的数据是存储到磁盘上的DB file 中,如果要修改或查询数据,需要将数据从磁盘加载到内存中。为了性能考虑,读取磁盘的DB file时,会每次读取一个页的大小,放到内存中的专门开辟的名字叫 Buffer Pool的地方。
-
Change Buffer
-
Buffer Pool 中专门划分了一块 Change Buffer,用来存储修改或新增的数据。
-
修改数据时,会先修改buffer pool中的页数据,如果修改了内存,还没有同步到磁盘,这些页被称为脏页。将内存数据同步到磁盘的动作叫做刷脏
-
当访问某修改的数据或者数据库关闭的时候,会将Change Buffer 中的数据存储到磁盘当中,这个过程叫做merge,
-
也有单独的线程做这件事 page cleaner thread(刷脏线程)。

-
-
如果存在某些场景频繁的写数据而很少读取,可以适当增大Change Buffer的空间来进行优化
-
- Adaptive Hash Index :为了提升Buffer Pool 中的热点数据访问效率,InnoDB引擎会为热点数据创建索引,即Adaptive Hash Index
- Log Buffer (Redo Log Buffer)
- 如果刷脏过程中,数据库停止运行将会导致内存数据丢失,为了解决该问题,InnoDB专门设计了日志文件,将所有的页操作写入这个文件,文件名称叫做Redo Log。有了这个文件,如果发生崩溃就可以通过该文件进行数据恢复。
- Redo Log Buffer是Redo Log 的缓冲池,它里面保存了要写入到磁盘文件的内容。主要还是为了减少磁盘IO次数。Log Buffer 区域默认大小16M
- 刷盘策略,由相关的参数
innodb_flush_log_at_trx_commit进行控制- 🏷
0: log buffer将每秒一次地写入log file中,并且log file的flush操作同时进行。该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。这个策略的性能是最佳的,但是会存在1s的数据丢失. - 🏷
1:每次事务提交时MySQL都会把log buffer的数据写入log file,并且刷到磁盘中去。这个策略能保证强一致性,也是InnoDB默认的配置,为的是保证事务的ACID特性 - 🏷
2:每次事务提交时MySQL都会把log buffer的数据写入log file。但是flush操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush操作。这种策略,如果操作系统出现崩溃,也可能会存在1s的数据丢失
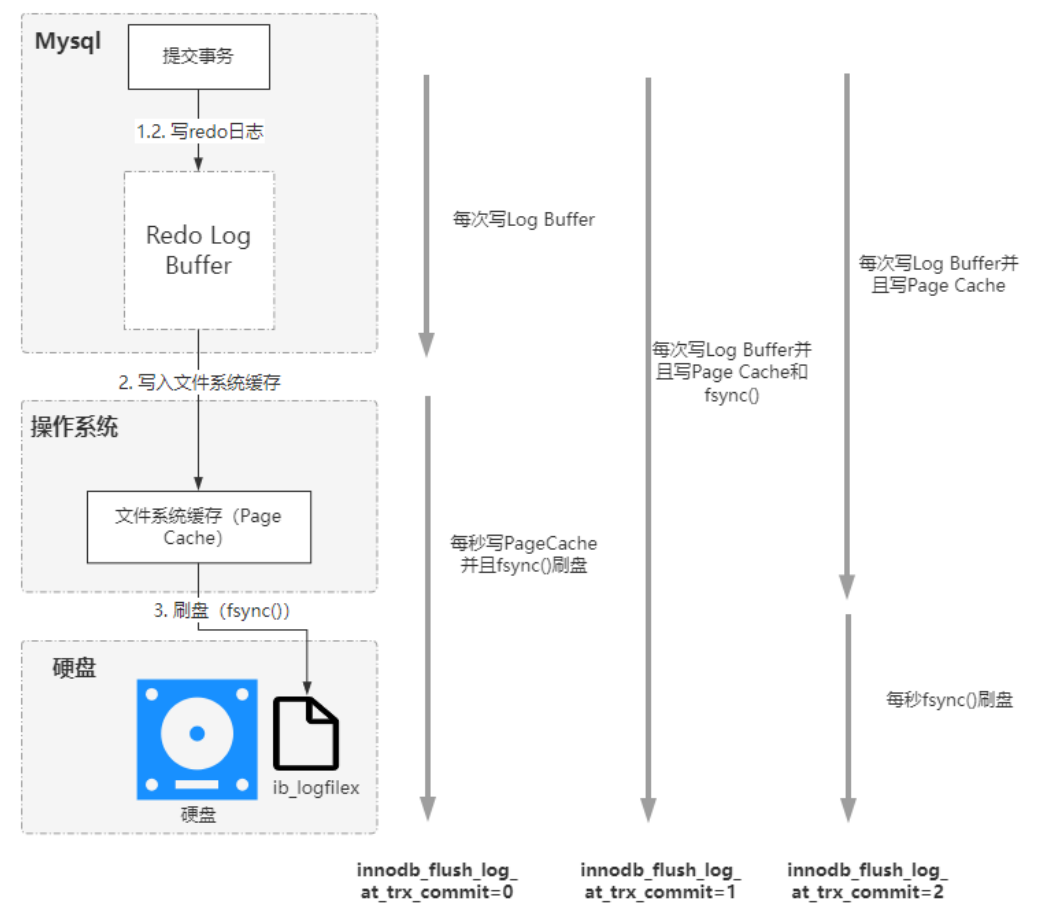
- 🏷
InnoDB磁盘结构
-
表空间结构
-
页(page):从磁盘加载数据到内存中有一个最小的存储单位:默认16K(16384 bytes)大小。每个页又包含许多数据行 (row)
-
区(extent):64个相邻的Page称为一个extent,每个区的大小为 1 MB。
InnoDB使用两种预读算法来提高I/O性能: 线性预读(linear read-ahead)和随机预读(randomread-ahead)。
🏷线性预读以extent(64个相邻的Page称为一个extent[区])为单位,
🏷随机预读以Page为单位。
-
段(Segment):多个区构成的逻辑单位
-
表空间由多个段组成

-
- 系统表空间(ibdata1)
- 系统表空间是共享的,如果每个表都使用系统表空间,那么系统表空间文件会不断变大,因此使用独占表空间来减少系统表空间的压力
- 独占表空间。每个表都有自己的文件,使用参数
innodb_file_per_table=on来指定开启,默认是开启的 - 通用表空间
- 使用命令
create tablespace ttttt add datafile '/var/lib/mysql/ttttt.idb' file_block_size=16k engine=innodb;创建一个名为ttttt的表空间。 - 创建表时可以指定该表使用表空间
create table aaa(id integer) tablespase ttttt; - 通用表空间的数据时可以移动的,如果要删除通用表空间需要删除通用表空间中的所有表
- 使用命令
- 临时表空间(ibtmp1)。包括用户创建的临时表,查询过程中产生的中间表
-
双写缓冲
-
部分写失效:页大小16K,磁盘的存储结构一般为4K,因此一个页的更改需要在磁盘中写入四个4K,如果只写入部分4K系统就崩溃了,就会导致部分数据丢失,称为部分写失效
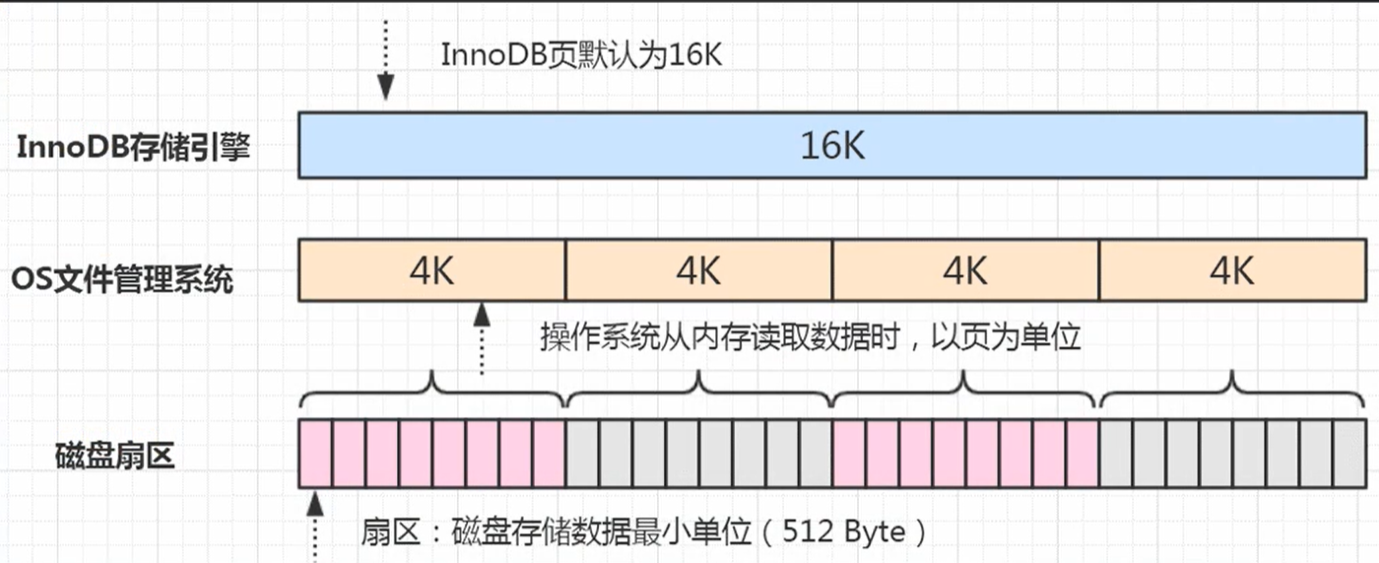
-
双写缓冲: 通过Redo Log 恢复是恢复一整页,所以对于部分数据损毁的页进行恢复是没有意义的。因此存储引擎会对每个页做一个副本,发生部分写失效时,会先通过副本来进行恢复页数据,实现数据页的可靠性,避免数据页本身破坏。这个副本机制就叫做双写缓冲。在磁盘中的文件格式
.dblwr
-
-
Redo Log
-
提供崩溃恢复的特性。
-
Redo Log在磁盘上有两个文件
ib_logfile0、ib_logfile1,每个大小为48M,写满之后新的内容会覆盖旧的内容。 -
有了Redo Log之后每次操作会先将内存数据记录到日志文件中,可以减少刷脏频率,提高系统吞吐量。
为了提高Redo Log的记录效率,专门分配Log Buffer 区域默认大小16M,Log Buffer 在写满之后就会同步到磁盘的Redo Log日志文件当中
写入Redo Log 是顺序IO ,而刷脏是随机IO,所以Redo Log 效率要高于刷脏
-
在磁盘上有两个文件
ib_logfile0、ib_logfile1,每个大小为48M,写满之后新的内容会覆盖旧的内容。有了Redo Log之后就会将内存数据记录到日志文件中,减少了刷脏频率,提高系统吞吐量。写入Redo Log 是顺序IO ,而刷脏是随机IO,所以Redo Log 写入效率要高于刷脏
-
- Undo 表空间
- 用来存储Undo Log,默认位于系统表空间,也可以独立出来。Undo Log 与Redo Log 一起被称为InnoDB的事务日志
- Undo Log 实现原子性,又叫撤销日志或者回滚日志,记录了事务发生之前的状态,属于逻辑日志
- Redo Log 实现持久性
- Bin Log
- 二进制日志,属于逻辑日志,记录了所有的DDL、DML操作日志,可以配合全量的备份实现数据库的数据恢复
- 可以通过Bin Log实现主从复制

索引
- 索引是一个排序的数据结构,用来协助快速查询数据,类似于书籍的目录

-
什么样的存储结构适合索引?
-
尝试使用使用二分查找提高效率,首先考虑Binary Search Tree。
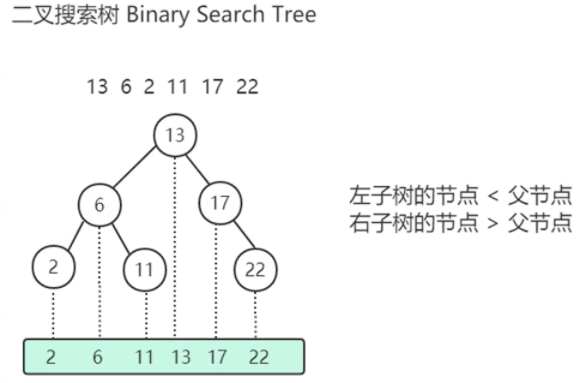
⚠ 存在问题:如果插入数据比如:
1\2\3\4\5\6会导致左右子树深度差太大,变成链表形式,所以不用此结构
-
使用平衡二叉树。左右子树深度差不会超过1,用来解决二叉树存在的问题。
- 如果使用该结构存储,那么结构如图
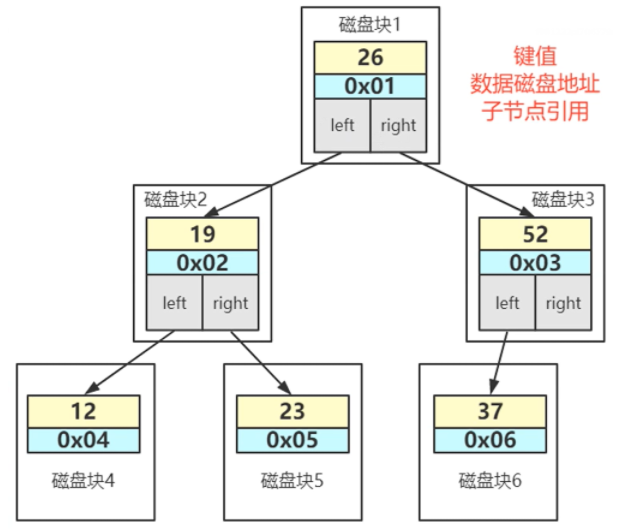
⚠ 存在问题
- InnoDB每次会读取一页,即16K大小的数据,如果这16K只用来存储 索引键值 以及 子节点的引用 会比较浪费空间
- 存储引擎访问一个节点就会发生一次IO操作,如果数据量过大,那么树深度较深,发生IO次数太多,非常影响效率
- 如果使用该结构存储,那么结构如图
- 使用多路平衡查找树。每个节点存储N个值的时候,会有N+1个度。通过树的分裂、合并来保持平衡
- 增加每个节点分裂的度,从而减少树的深度,解决平衡二叉树存在的问题。
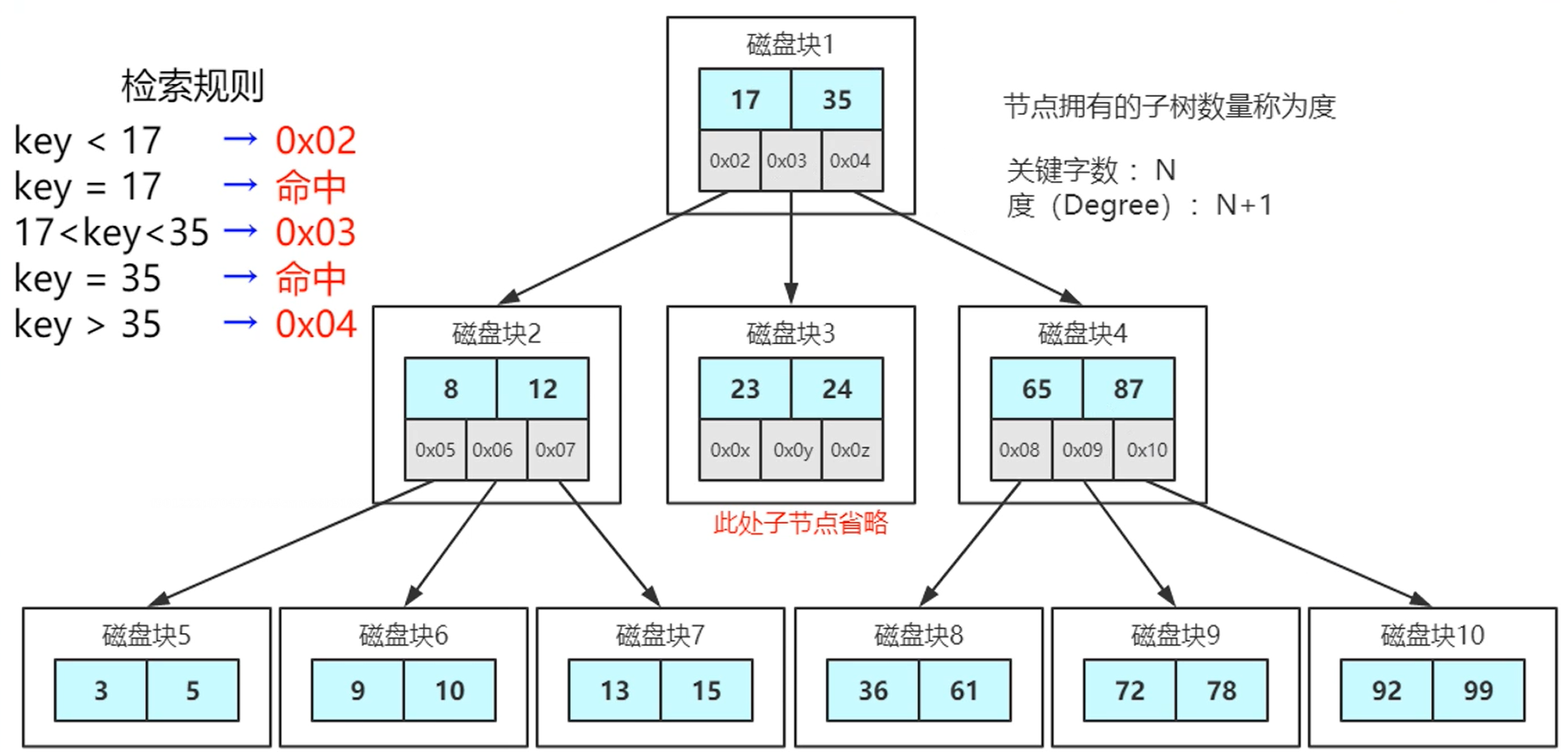
- 当一个节点存储更多的数据时,树的深度就会减少。
- 增加每个节点分裂的度,从而减少树的深度,解决平衡二叉树存在的问题。
- 使用多路平衡查找树已经可以解决问题了,但是在InnoDB中采用了更加优化的B+ Tree树作为存储结构
- B+ Tree只有叶子节点存储数据,非叶子节点只存储索引值以及节点指针。
- 相邻叶子节点之间有个指针,这样存有数据的叶子节点形成了一个有序的链表结构,提高了范围查找、排序的效率。
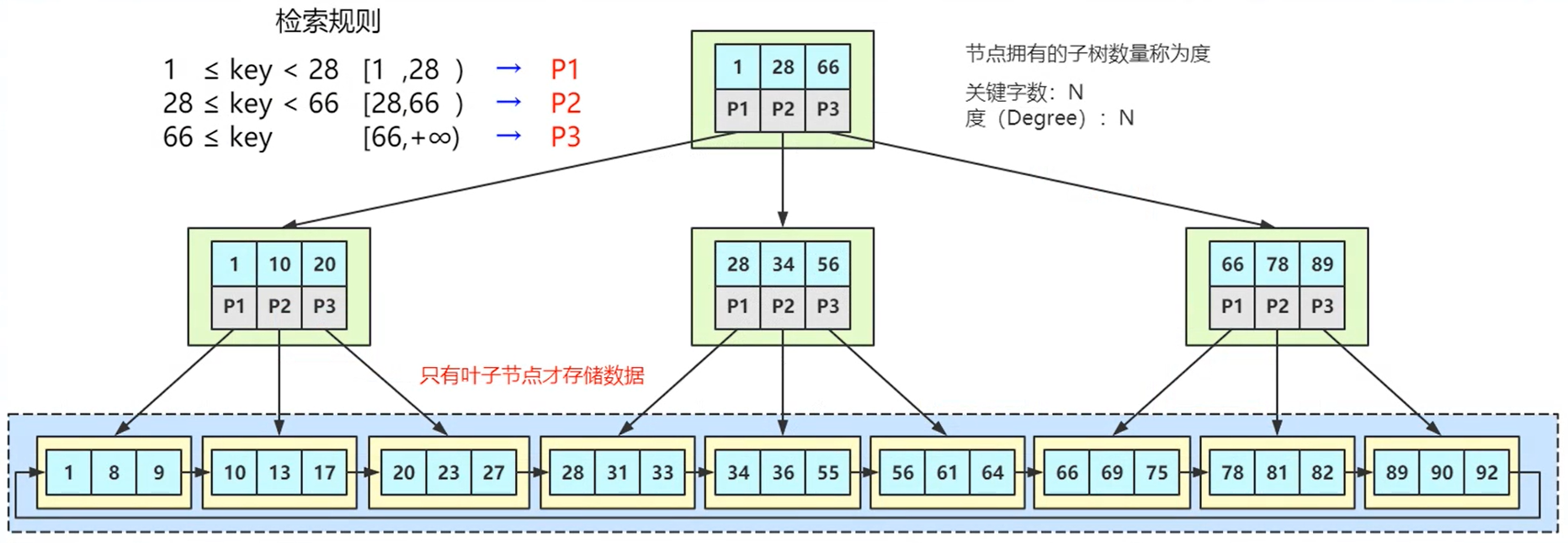
- 可以较小的IO次数存储较多的数据
🏷一个节点的大小为16K,即16 * 1024 = 16384字节。- 假设索引值类型为bigint,那么一个数值索引占用的空间为 键值(8字节)+ 指针(固定为6个字节)= 14字节。
- 那么一个非叶子节点能存储 16384 / 14 = 1170 个索引,那么树的度数为1170
- 假如一条记录大小为1K,那么3层高度的树能存储1170 * 1170 * 16 = 21902400条记录
- 相较于B tree。B+ tree 扫库扫表能力比更强、磁盘读写能力更强、排序能力更强、效率更加稳定
-
-
不同的存储引擎对于索引的实现有所不同
-
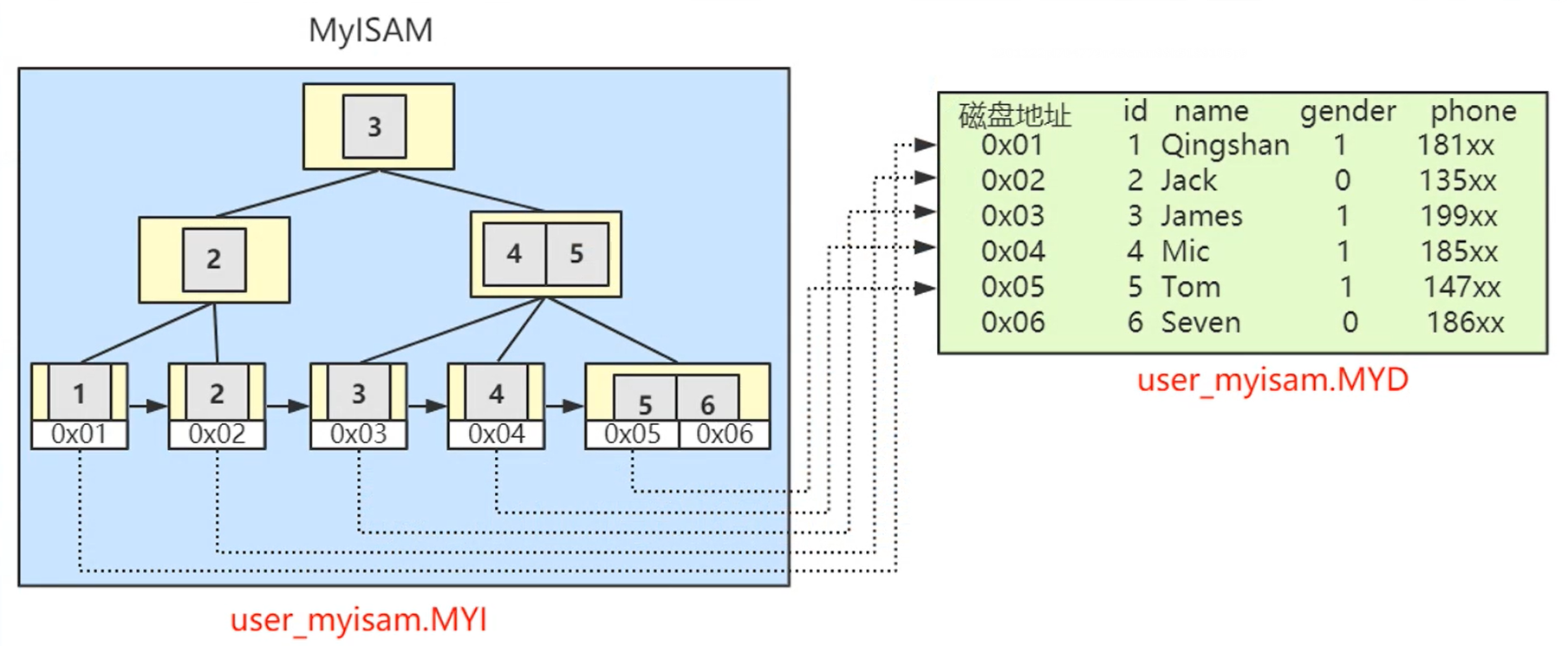
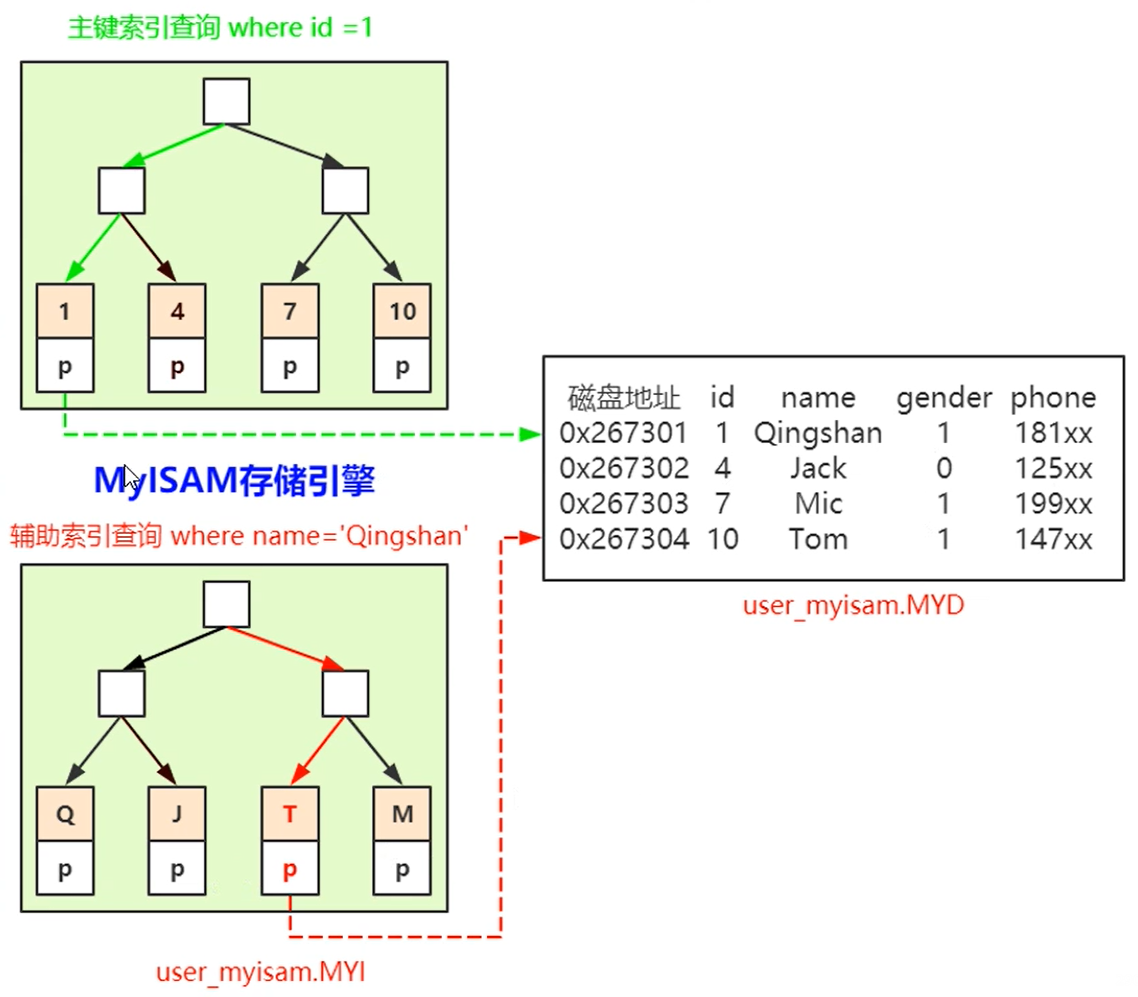
MyISAM 引擎的索引与数据是分开的,位于两个文件之中,数据位于MYD文件,而索引位于MYI文件中
-
主键索引与普通索引都位于MYI文件中,查询数据的方式没有区别
-
-
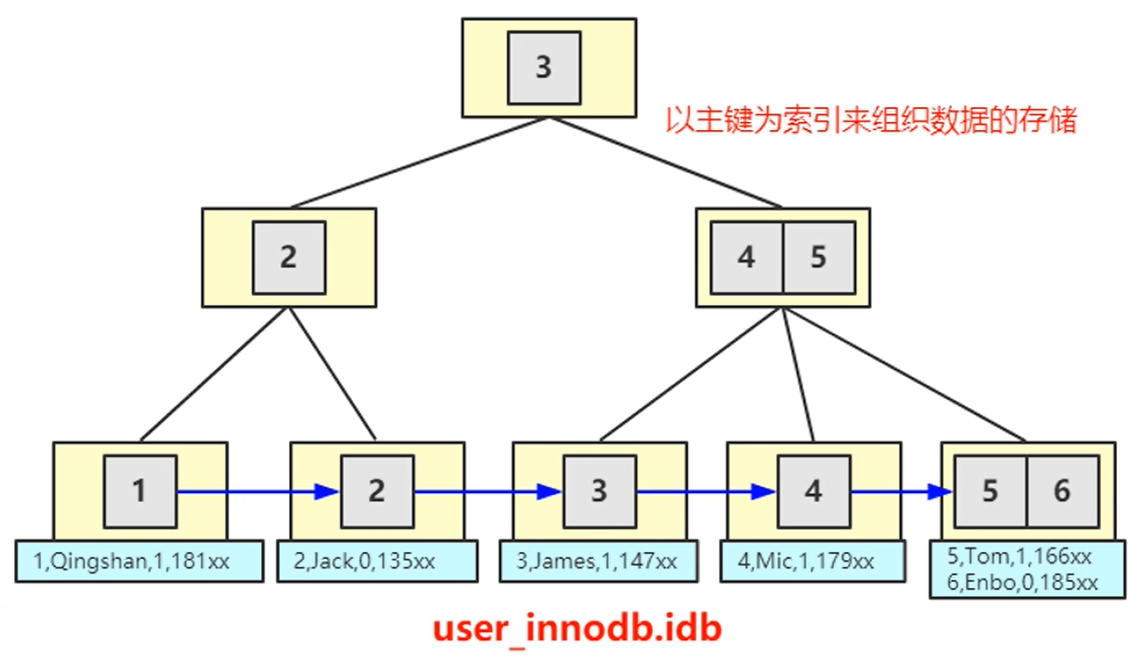
- InnoDB引擎的数据和索引是在同一个IDB文件中
- 主键索引只有一个,主键索引的叶子节点对应了具体的数据。而普通索引叶子节点存储的是主键索引,而不是具体数据
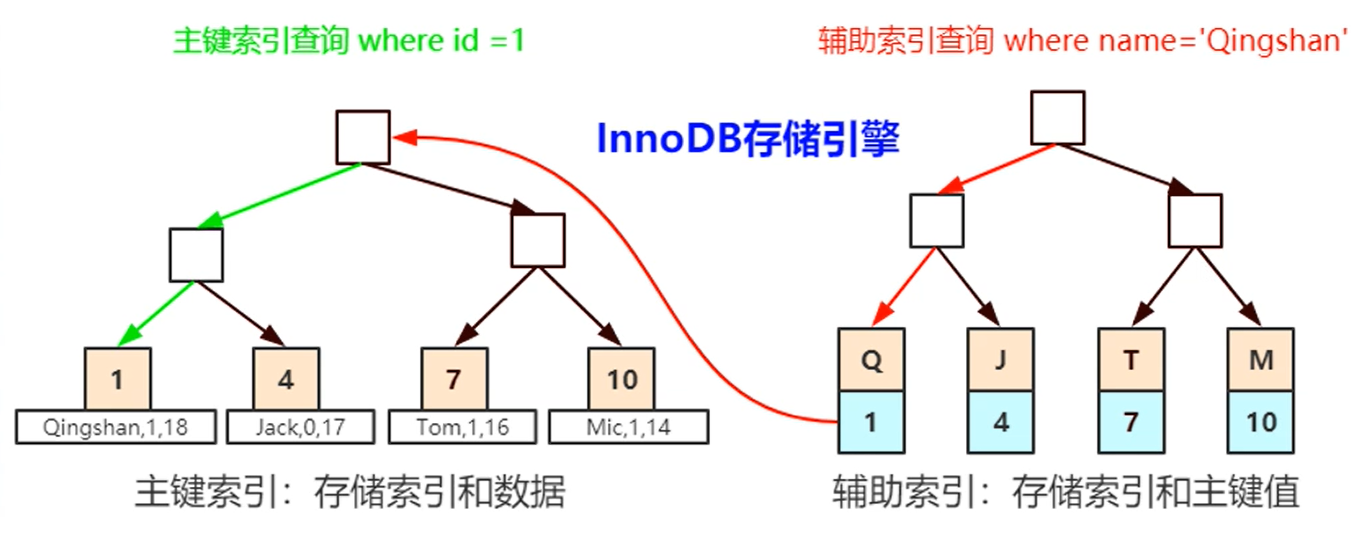
- 主键索引只有一个,主键索引的叶子节点对应了具体的数据。而普通索引叶子节点存储的是主键索引,而不是具体数据
- 聚集索引:决定了数据存放顺序的索引叫做聚集索引,聚集索引是一定存在的。
- 如果有主键索引,那么主键索引作为聚集索引
- 如果没有主键索引但有唯一索引且唯一索引不包含空索引,则使用唯一索引作为聚集索引
- 如果以上情况都没有那么会使用隐藏的ROWID作为聚集索引
-
索引创建原则
-
在用于where 条件、order排序、join on字段上的字段创建索引
-
创建索引个数不要太多
-
离散度(区分度)低的字段不要创建,如性别,否则优化器会放弃使用索引
公式重复的数据量/数据总量,比如性别字段的数据离散度很低
-
多个字段需要索引时,尽量创建联合索引,而不是多个单索引。创建联合索引时尽量把离散度高的字段放到前边
多个字段创建的索引,遵循最左匹配原则,从最左边开始,不能中断
-
过长的字段使用前缀索引,如:
alter table x_test add index(x_name(1))为x_name字段的第一个字符创建索引 -
覆盖索引:所有的查询字段包含在了索引字段之上,比如
select name from user where name='张三'就是使用覆盖索引 -
查询使用索引,尽量避免回表
InnoDB的索引检索是有两颗树,一颗是主键索引树,一颗是辅助索引树,多扫描一颗树的过程叫做回表,回表会带来额外性能开销
-
最终有没有使用索引,是由优化器决定的。
例:为表
user创建联合索引name,phone正常情况下:
select * from user where phone = '18755556666';是使用不到索引的但是
select phone from user where phone = '18755556666';是可以使用到联合索引的,原因是执行时的优化器做了优化
-
- 用不到索引的情况
- 如果索引列上使用了函数、表达式、计算等情况
- 字符串类型的值,不加引号,出现了隐式转换
- like 条件中前面带 %
- 负向查询有些用不到 not in ,具体情况要看优化器的选择,基于成本的优化